머신러닝의 학습방법은 크게 지도학습, 비지도학습, 강화학습 세가지로 나누어집니다.
인공지능을 깊게 공부하지 않으신 분들도 알파고쇼크를 통해 위 세가지 학습법의 이름이라도 들어봤을 것 같습니다.
알파고의 경우 지도학습을 통해 바둑 기보를 학습하고 강화학습으로 최적화되었다고 합니다.
그런데 과연 지도학습은 뭐고 강화학습은 또 뭘까요? 각각 어떤 상황에 사용해야 할까요?
이 글을 통해 머신러닝의 세 학습법에 대해서 알아보고 원하는 결과를 얻기 위해 어떤 학습법을 사용해야 하는지 생각해봅시다.
feature에 대해서
들어가기 전에, 지도학습, 비지도학습, 강화학습 모두 적절한 feature를 정의하는 것이 중요합니다.
feature란 한국어로 특징이라고도 부릅니다, 말그대로 어떤 사물의 측정 가능한 속성이나 패턴을 뜻합니다.
고양이를 분류하는 인공지능 모델이라면 뾰족한 귀의 모양이나 눈코입의 개수 등이 feature가 될 수 있겠죠.
feature는 label, class, target, response, dependent variable 등으로도 불립니다.
지도학습 (Supervised Learning)
정답을 알려주면서 학습시키는 방식을 뜻합니다.
사진의 손모양이 가위인지, 바위인지, 보자기인지 분류하는 알고리즘이라면
input받은 사진에 이 사진은 가위입니다 라는 lable값이 붙어 있어야 합니다.
답이 정해져 있는 만큼 기계가 답을 맞췄는지 아닌지 알기 쉽습니다.
지도학습은 크게 분류(classification)과 회귀(regression)의 두가지로 나뉩니다.
1-1) 분류(classification)
예측해야 할 데이터가 범주형(categorical)일때 분류라고 합니다.
- 이진 분류
어떤 데이터에 대해 두 가지 중 하나로 분류할 수 있는 것.
ex)
Q: 이 글은 스팸이야?
A: 예 또는 아니오
- 다중 분류
어떤 데이터에 대해 여러 값 중 하나로 분류할 수 있는 것
ex)
Q: 이 동물은 뭐야?
A: 고양이 또는 사자 또는 강아지 등...
1-2) 회귀(regression)
예측해야 할 데이터가 연속적인 경우(숫자로 나타낼 수 있는 경우) 회귀라고 합니다.
ex)
Q: 어디 동네에 어떤 평수 아파트면 집 값이 어느정도야?
A: 어디 동네에 24평이면 얼마, 어디 동네에 32평이면 얼마, 어디 동네에 45평이면 얼마
2. 비지도학습(Unsupervised Learning)
지도학습과는 달리 정답을 알려주지 않고(label이 없음) 비슷한 데이터를 군집화 함으로써 학습합니다.
위의 고양이 사진을 분류하는 예시와 같이 feature가 명확하지 않은 경우, 지도학습에 필요한 적절한 feature를 찾아내기 위한 데이터 전처리 기법으로도 사용됩니다.
대표적인 알고리즘으로는 클러스터링, 차원 축소 등이 있습니다.
클러스터링 : 특정 기준에 따라 유사한 데이터끼리 그룹화
차원축소 : 고려해야할 변수를 줄이는 작업, 변수와 대상간 진정한 관계를 도출하기 용이
3. 강화학습(Reinforcement Learning)
강화학습은 지도학습, 비지도학습과는 조금 다른 개념입니다.
바둑과 같이 무수히 많은 경우의 수가 있어 정답이 따로 정해지지 않은 환경에서 최고의 보상을 얻을 수 있는 값을 찾아내는 알고리즘입니다.
정답을 찾기보다는 무수히 많은 시도를 통해 더 많은 보상을 얻을 수 있는 action을 탐색합니다.
강화학습만의 구분되는 특징은 시행 착오(Trial-and-error)와 지연 보상(delayed reward)입니다
사이킷런
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
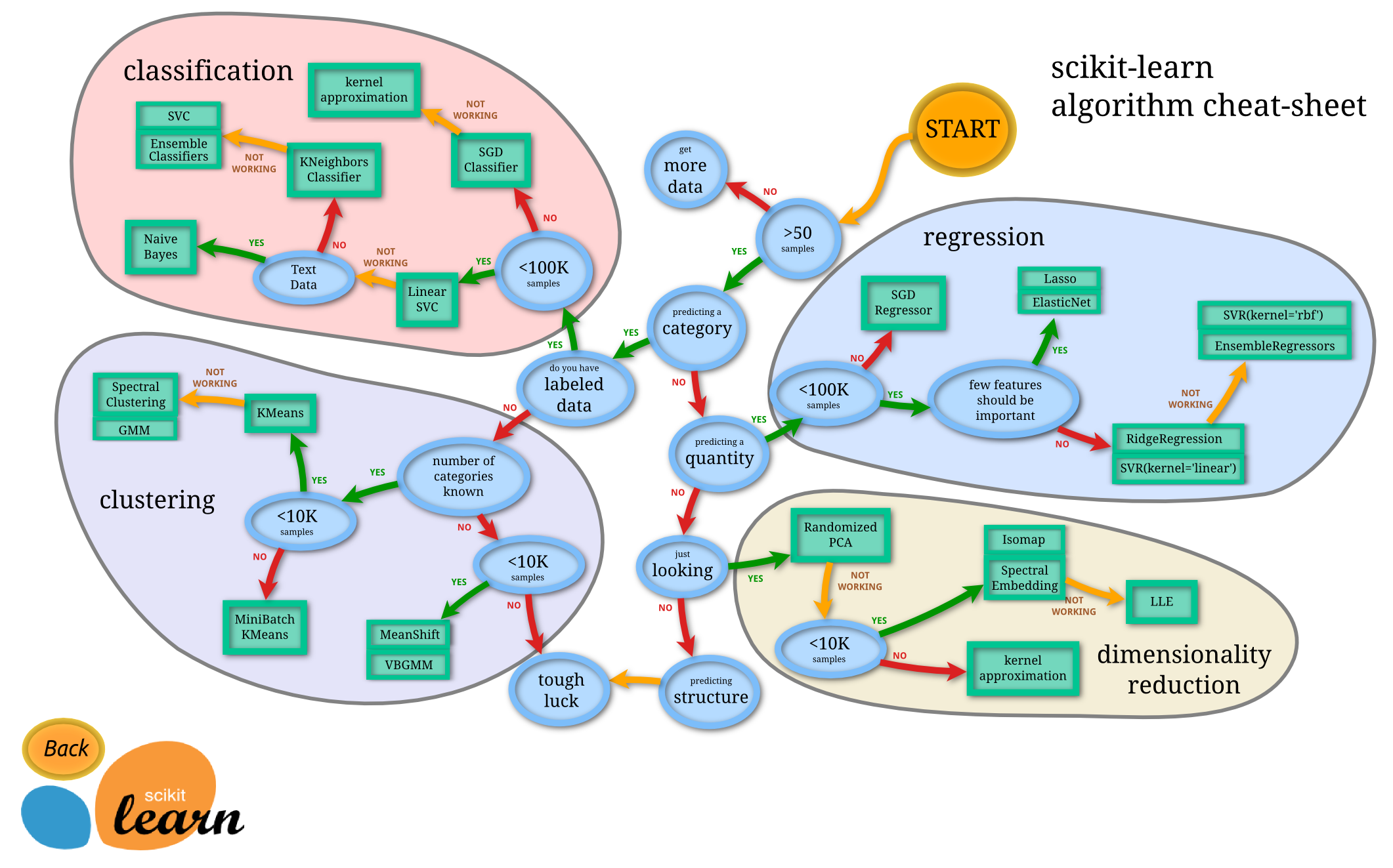
위 이미지는 사이킷런에서 제공하는 최적의 알고리즘을 찾는 알고리즘입니다.
데이터가 얼마나 많은가? 데이터가 정답(label)이 있는 데이터인가? 데이터가 수치형 데이터(quantity)인가, 범주형 데이터(category)인가? 등으로 머신러닝에 최적의 알고리즘을 찾을 수 있게 도와줍니다.
Classfication(분류), Regression(회귀), Clustering(군집화), Dimensionality Reduction(차원축소)의 4가지 task로 나누었으며 위에서 살펴본 지도학습과 비지도학습의 분류와 같습니다.
이를 참고하면 적절한 머신러닝 알고리즘을 찾아내기 편리할 것 같습니다.